This is the article version of the invited talk I gave at the BSC AI Factory of Barcelona, during a CARTO event. The title ‘Earth Intelligence’ sounds like science fiction or philosophy. It isn’t. This is not a wish list for future data or tech I wish we had. We do in fact have enough data and tools. This is about the simplest, fastest way to access planetary insights right now. What a time to be working on this!
For this piece I’m focusing on Earth Intelligence as in global search (“where is what”). We do have the questions. To know where the fires are starting, the forests are disappearing, the infrastructure is crumbling, tanks rolling or crops flooded. The problem—which many others are also seeing—isn’t the lack of demand or curiosity. Or even the lack of data. The problem is the effort to get an answer.
Current tools are slow, expensive, and difficult to understand or scale. Or as acronym lovers would say, we have a serious and clear case of DRIP: Data Rich, Information Poor. We live on a “DRIP Earth.” A planetary Diogenes syndrome—we hoard petabytes of data for the “best-case scenario” that 10% of it might be useful one day in the future. We know how to “write”, but not how to “read”.
So, clearly, “Earth Intelligence” does not live in the data. Nor does it live in the compute, if we can’t read at scale. So where is that missing source of planetary Intelligence? AI, of course. AI for Earth brings really powerful tools, and new options. I see three big ones. A game of Choose Your Own Adventure :
Door #1: Intelligence is Thinking. AI scales thinking via Agents.
Door #2: Intelligence is Compression. AI embeddings enable smart compression.
Door #3: Intelligence is Retrieval. AI enables simple search.
Door #1: Intelligence is a Process (Agentic AI)
This is the vision currently best developed with Google’s Earth AI
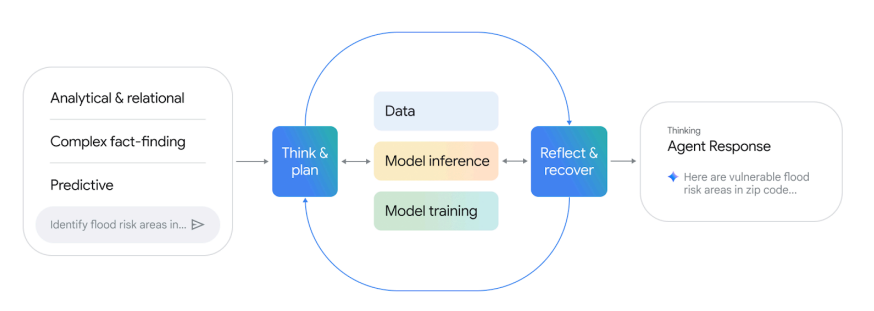
The Agentic loop of Google’s “Earth AI”
The premise here is that intelligence is a dynamic process that depends strongly on local and topic expertise. When you ask a question like “Find vulnerable flood zones in Mumbai,” an AI Agent spins up. It acts like a Super Consultant :
Decomposition: Breaks the question into steps.
Tool Selection: Picks the right API or dataset.
Execution: Fetches raw pixels, trains or fine-tunes models, and runs heavy inference.
Synthesis & Self-Assessment: Reviews answer, and cycles the whole process again in a loop until it finds a defensible answer.
Besides the agent, the crucial step is that it leverages base models that are fine-tuned for each specific question, data, and location. The idea is that these models are the undifferentiated general compute all answers need, so the last step of fine-tuning is an extremely efficient way to get great local answers. It combines the general power of a global baselines, with local and subject matter expertise and needs for a local answer.
Clay was originally created with this mindset. But we soon realized that we could finetune the embeddings of the base model and bypass the need to access raw data or do heavy inference every time.
The latest iteration of this base model plus finetune is Olmo Earth, by Ai2. Ted Schmitt explicitly mentions the core decision to “go beyond embeddings and enable fine-tuning and allow an ecologist or a local community member to go in and tune our foundation model and deeply inform that model with their expertise”. So they also built a custom platform to enable this with no-code to make it as easy as possible. A few years ago, at Microsoft, we built a similar open-source model and platform with PEARL and the Planetary Computer (only for land cover and land use).
I’ve known, traveled and used this door. It provides great answers. Unfortunately it comes with significant hidden costs**:**
Slow: You are running a new scientific study for every single query.
Expensive: You aren’t buying an answer; you are procuring a massive amount of compute to “re-read” the library every time. This is a great cloud business, but hard to sustain as a non-profit service, and hard on the environmental footprint, even with finetune.
Brittle: The non-deterministic nature of agents means that every run might yield a different answer. In most cases the local expertise can induce model collapse in hidden ways that are hard to detect. A bad label from an expert, or even a good label with a noisy data representation can silently bias the output.
Captive: You are dependent on the platform’s orchestration. With no SLA or open standards, your investment sinks if the platform closes. Neither Google’s Earth AI or Olmo Earth platforms have SLA commitments to set future expectations to base critical dependencies. Or are open source (Olmo Earth model is, with a custom open license) so you can deploy elsewhere, or are standards for which similar options are available.
Door #2: Intelligence is Compression
This vision believes intelligence is compression—squeezing the pixels of the world into dense, rich mathematical vectors that are smart enough to disregard noise (clouds, shadows) and save only the signal. Think of this as creating a “Zip file” for the planet. Examples include Clay , SatCLIP , Tessera , Alpha Earth… Models with which you can make embeddings, or they also provide large collections of embeddings ready to use.
A huge upside is that you can directly use the much smaller embeddings and not need to access, or process raw data. There are countless benchmarks that prove these embeddings can achieve very high scores for “Earth Intelligence” questions like flood detection, or crop monitoring.
Like foundation models, these embeddings already incorporate most of the compute needed to get those answers, and you can even “finetune the embedding” faster than the entire base model. Like many others still do, we saw them as the goldilocks with all the benefits of Earth data without the large storage, compute or noise. We still do, but the more we use them, from different datasets, models and applications, the more we realized there are also hidden costs:
“Cognitive Debt”: Every time you compress raw reality into a vector, you make invisible choices about what matters. You often trust the models that made them much more than we understand the biases and silent failures they might introduce. These design choices and bugs are much harder to detect since these compressions are hard to understand directly. Have you ever opened a zip file directly?
“Decoder Tax”: These embeddings are “Training-Ready,” not “Analysis-Ready.” You still need high skills to use them. You must use a complex decoder that also introduces many decisions and limitations.
“Coiled Trap”: A zip file is smaller, but you can’t search inside it without unzipping it. In many cases it is the pair encoder-decoder that is built in parallel, which allows extremely efficient compressions, but also extremely complex to understand. Compressions and explainability are probably opposing forces where neither extreme is optimal.
Before going to the last door, both above approaches introduce a profound problem brilliantly explored by Simon Ilyushchenko. He argues that converting raw geospatial data into any derivative inevitably sacrifices deep realities for shallow metrics, introducing structural errors like spectral ambiguity and scale mismatches. This becomes dangerous when AI agents process data without the “epistemic friction” and context-aware skepticism of human analysts. If your outputs cannot be easily mapped to the original data, you are not only trusting the abstraction it made, you are stunting any answer to the hidden assumptions, and errors, of that process.
Door #3: Intelligence is Retrieval (The Search Engine)
This is the path we are betting on. It is a subtle but critical twist of the compression above. We work hard to make compressions… that are simplest to use—to the point that they cease to be just compressions, but an Index of the content.
We believe the highest bar for useful compression is one that allows the simplest search. We call this the “Linear Bet” : That simple proximity lookups on an Index are enough to find most things. We are not alone seeing this. There has been immense progress in the text domain. A few years ago in geo, Earth Genome founders and team demonstrated the potential of this approach with “Earth Index”.
We now have strong indications this is possible at global, historical, multimodal scale. Just to name one, using Google’s AEF model, Samuel Barrett found direct lookups for very specific concepts like “Black Beaches,” “The Northern edge of fields in Wales,” or “Piers on airports.”
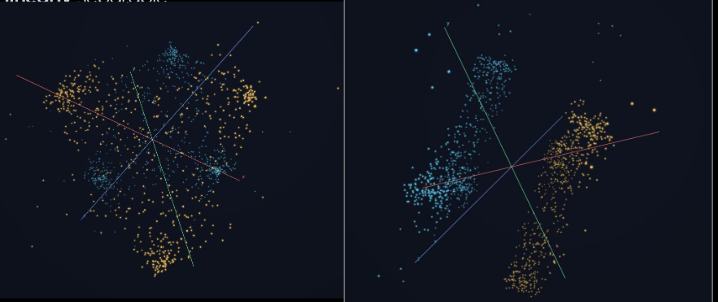
Same distributions of plots. Left: A Random Forest or similar will probably do a good job separating classes, but if you rotate the space (right) it becomes extremely simple to separate with a line. Credit Sam Barrett.
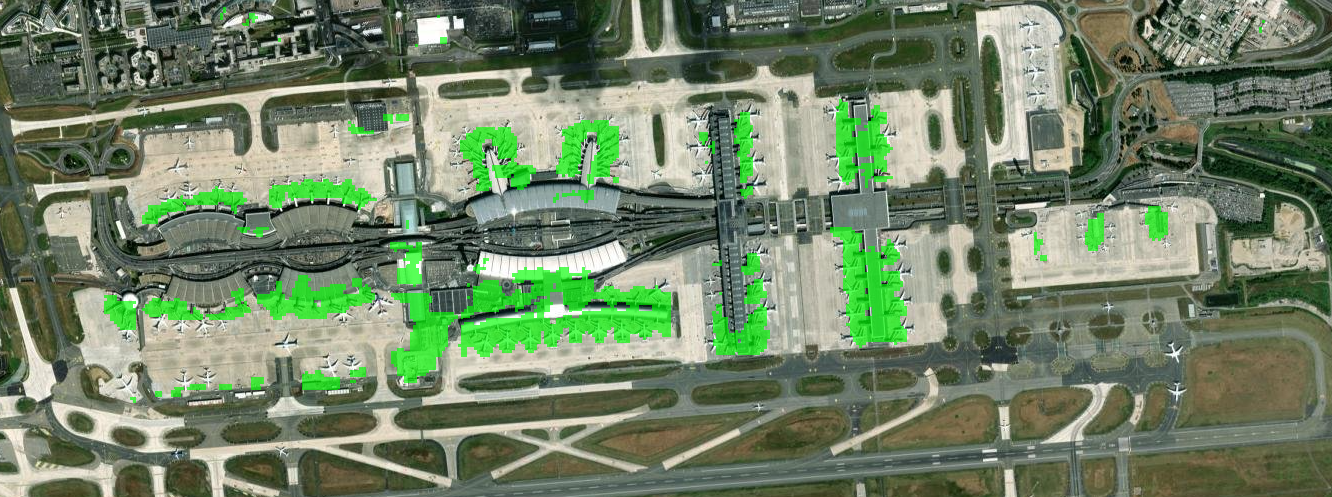
There is a linear direction in Google AEF embeddings that directly points to piers of airports. An example of very specific semantics that can be directly encoded. Credit Sam Barrett.
Moreover, just like it has been discovered for text embeddings, these linear searches allow a new kind of Earth Algebra:
This is the promise of Planetary Scale zero-shot retrieval.
Why we are going all-in on this:
Fastest Time to Answer: Nothing comes close to getting something useful this fast.
Minimal Marginal Cost: The cost of each question is effectively nil (a linear lookup), with no computer vision, pixel math or other inference.
Iterative Convergence: We can quickly improve answers by leveraging user expertise in real-time.
Minimal Cognitive Load: The user doesn’t need to know what an “embedding” is. It’s just search.
Transparent Choices: Index-based search re-ranks real raw data, overcoming the hidden choices of inference.
Sneak beta preview of LGND AI, Inc. — which we will soon release: find new solar panels, in seconds:
(Video available on LinkedIn)
Here Be Dragons

If you look at ancient maps, cartographers put “dragons” to symbolize the dangers hidden in unknown territories. We find similar dangers here. There’s a lot we don’t know. We expect setbacks and unexpected benefits. Routinely we find that embeddings defy intuition, and the temptation to use complex decoder prevails on most people doing compressions. To the degree we can stick to linear tools, we’ll be painting a new kind of map that helps us navigate these limits. The best part of this approach is that our evaluation is extremely clear and simple: “Does it find it?” This aligns fully with user intent. We don’t create abstractions in the output, we point to the relevant data, like a search engine.
For example:
Semantic envelope : we don’t know what semantic range or complexity we can achieve. Bridges on high resolution? For sure. Deforestation? (temporal dependency) also. But can the index see beyond what humans do? Can we index types of cars on 10m resolution? Can we find the semantic of “vulnerable infrastructure"?
Bootstrapping the Index : Clearly we can look by proximity when we have examples (“More like this”), but we also need to use text (“bridge”). This cross-modality is not easy, especially when we think of languages, synonyms, acronyms (“CAFO”), homonyms (“Bank” can be different things), … This is especially hard when you not only search for things, but for changes, or other abstractions.
Can we flatten all queries? A recent Google DeepMind paper proved that embeddings have hard limits to retrieve specific text combinations. I believe geoembeddings can bypass most of these limitations using geo-specific attributes like location and time. One of the benefits of linear lookups is that we can easily compose them, and also decompose complex queries (deforestation decomposes into “forest that in time cease to be forest”).
Pixel mindset. Probably the biggest challenge is that the more you know about GIS and EO, the more your skills and thinking are biased towards pixels and maps. It is hard to avoid sliding into it.
All of the Above
This piece is intentionally opinionated to spark debate and conversation, and to highlight the power of less traveled road, the Index search. I have the highest respect for all teams and services mentioned above, and I know I missed many more. Obviously, the right approach is not just one option, but a sequence of them: It makes the most sense to do an Index search for candidates, and then turn over to heavier models or Agents to validate the now much reduced workload. For example, if you want to find new solar panels in Texas:
Don’t run computer vision on the whole of Texas at all time steps.
Index it once. Get all locations with >70% probability.
Then apply your heavy models on the few pixels that matter.
We are moving from a world where we stare at maps, to a world where we simply ask the index.
